There are times where you want to access your S3 objects from Lambda executions. It’s a pretty simple process to setup, and I’ll walk us through the process from start to finish.
To begin, we want to create a new IAM role that allows for Lambda execution and read-only access to S3. If you want write access, this guide is still relevant, and I’ll point out what to differently.
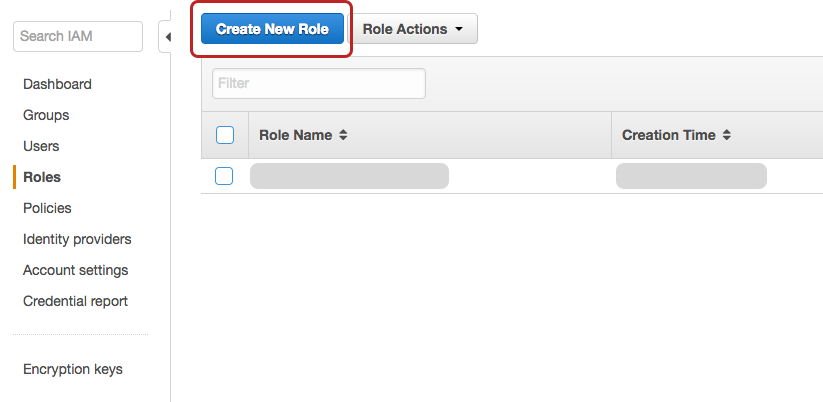
Navigate to the IAM service portion, and move to the Roles tab on the left. Next, we want to create a role - the name isn’t too important, just keep it something easy to comprehend. For example, my new role’s name is lambda-with-s3-read.
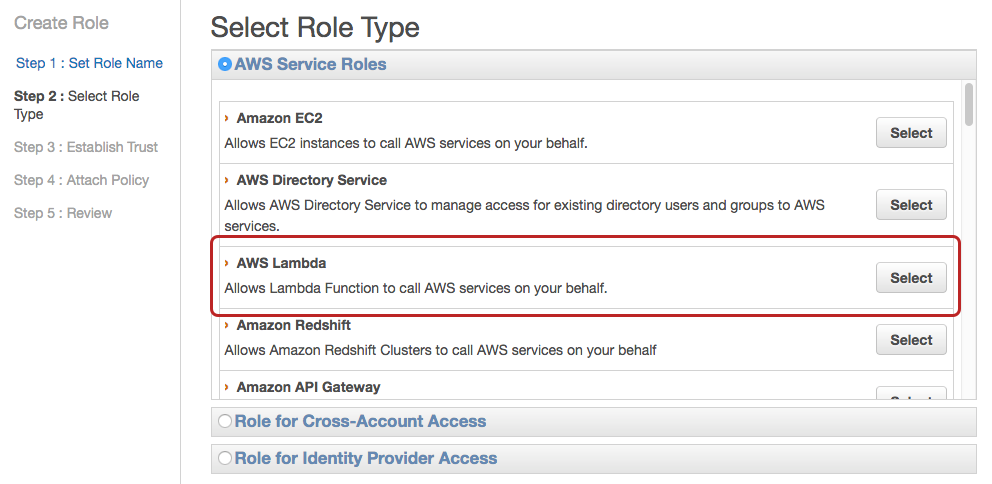
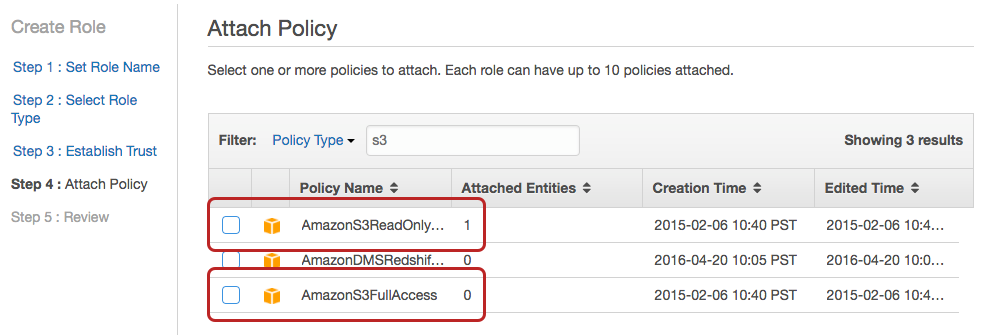
We now want to select the AWS Lambda service role. From there, it’s time to attach policies which will allow for access to other AWS services like S3 or Redshift. As shown below, type s3 into the Filter field to narrow down the list of policies. If you want your Lambda function to only have read access, select the AmazonS3ReadOnly policy, and if you want to put objects in, use AmazonS3FullAccess.
After that, you can review one more time before creating your new role. We can now hop on over to the Lambda home page to create a new Lambda function. Below is some super-simple code that allows you to access an object and return it as a string.
import json
import boto3
s3 = boto3.client('s3')
def lambda_handler(event, context):
bucket = 'test_bucket'
key = 'data/sample_data.json'
try:
data = s3.get_object(Bucket=bucket, Key=key)
json_data = data['Body'].read()
return json_data
except Exception as e:
print(e)
raise eThis method checks for an object at data/sample_data.json in test_bucket. It uses boto3, the Python AWS library. The key method in this code is get_object. This returns a dictionary with the following syntax:
{
'Body': StreamingBody(),
'DeleteMarker': True|False,
'AcceptRanges': 'string',
'Expiration': 'string',
'Restore': 'string',
'LastModified': datetime(2015, 1, 1),
'ContentLength': 123,
'ETag': 'string',
'MissingMeta': 123,
'VersionId': 'string',
'CacheControl': 'string',
'ContentDisposition': 'string',
'ContentEncoding': 'string',
'ContentLanguage': 'string',
'ContentRange': 'string',
'ContentType': 'string',
'Expires': datetime(2015, 1, 1),
'WebsiteRedirectLocation': 'string',
'ServerSideEncryption': 'AES256'|'aws:kms',
'Metadata': {
'string': 'string'
},
'SSECustomerAlgorithm': 'string',
'SSECustomerKeyMD5': 'string',
'SSEKMSKeyId': 'string',
'StorageClass': 'STANDARD'|'REDUCED_REDUNDANCY'|'STANDARD_IA',
'RequestCharged': 'requester',
'ReplicationStatus': 'COMPLETE'|'PENDING'|'FAILED'|'REPLICA',
'PartsCount': 123,
'TagCount': 123
}It’s a pretty complicated object, but the one we care about is Body, which holds a StreamingBody with a method read that returns a string. You can learn more about get_object in the documentation. Once you load this in as a string, you can parse it as JSON or do anything else you’d like with it before returning.
And with that, we’re all done! You know how to access your S3 objects in Lambda functions, and you have access to the boto documentation to learn all that you need.